Introduction to CNN
Deep learning is one of the most if not the most trending fields in Computer Science right now both in academic research and industrial applications.Companies like Google and Facebook use deep learning as a tool to enhance user experience and interaction as well as to introduce applications like Image recognition, Voice recognition, Machine Translation etc. to be used in real time.Introduction of Deep learning is a huge step forward towards generalised AI.
One of the applications of Deep learning is Image recognition.Image recognition has many applications ranging from Face recognition for security to powering autonomous vehicles.Image recognition using deep learning is what brought deep learning into the prominence when a CNN architecture named AlexNet[1] beat standard algorithms for image recognition in the ImageNet Large Scale Visual Recognition Challenge[2] beating the runner-up by more than 10% error rate.
Now what exactly is CNN? Well for beginners it stands for Convolutional Neural Network, It is a type of neural network architecture which is primarily used for Image recognition tasks.Now why don’t we use normal neural network architectures for image recognition?Well the primary reason is that a normal neural network architecture is not able to identify the spatial context of pixels in an image which makes it less accurate than using CNNs.
A Convolutional Neural Network or CNN has two types of layers Convolutional Layers and Pooling Layers.Before going into that we need to understand what makes up an image.A simple grayscale image or a black and white image is made up of pixels in a grid which has ‘R’ rows and ‘C’ columns thus has a dimension of R x C.Each value in the grid represents the intensity of the pixel.Similarly a coloured image has 3 grids stacked on top of each other one for each colour channel RGB.This adds one more dimension nc thus a coloured image has a dimension of RxCxnc where nc represents the number of channels.
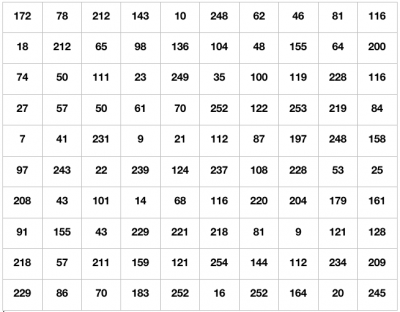
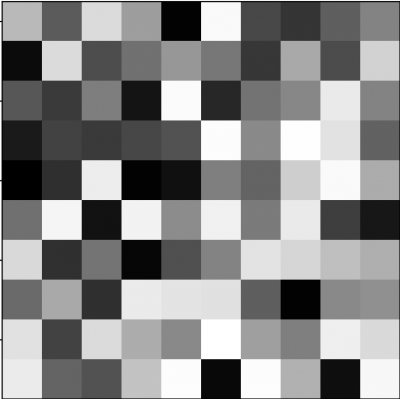
Fig.1:Grayscale Image grid and equivalent image
Convolutional Layers use filters of dimension nxnxnc. What are Filters?Filters are multidimensional matrices which are imposed on the image grid from the top left to the bottom right to find an output, here each has a depth of nc thus every layer of the output represents the output of of imposing a single filter on the image grid thus the number of channels in the output of a certain layer depends on the number of filters used in that layer.Now these filters have learnable parameters and thus these filters are updated after each iteration via backpropogation.
Pooling layers also known as subsampling layers are used to reduce the number of parameters by selecting appropriate parameters to propagate forward,There are many methods to do this but the most popular right now is max pooling where the maximum value is chosen in every nxn region from top left to bottom right and repeated for every channel in the input.
Now that we have a vague understanding of Convolutional and Pooling layers let’s understand how these are used to make a CNNs which are used for various tasks.After looking at various well known CNN architectures like LeNet and VGG-16 it’s quite clear that CNNs follow a certain pattern ie. There is a pooling layer after a certain number of convolutional layers and that the number of channels increase as we move deeper into the layer while the other two dimensions decrease, this is a common pattern in most if not all CNNs.Fully connected layers are usually used as the last few layers of a CNN for classification or other such tasks.
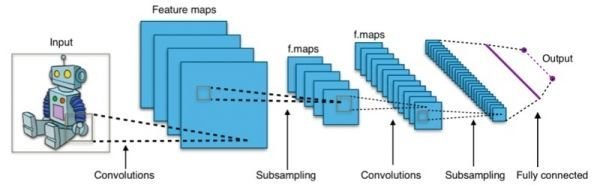
Fig.1:A common CNN architecture